Training a large language model is expensive once. Serving it is expensive forever. Every query a user sends spins up a full forward pass through billions of parameters, and those parameters must be streamed from GPU memory on every single token generated. The machine that took months and millions of dollars to train now sits waiting for requests, burning roughly $2–4 per hour per A100 whether or not anyone is talking to it.
The gap between what inference hardware can theoretically do and what naive serving actually achieves is enormous. A single request on an 80GB A100 might use under 5% of the GPU's floating-point throughput. The rest is wasted — spent waiting for memory reads. This post is about the engineering that closes that gap: how real inference systems think about batching, memory, scheduling, and the dollars-per-token arithmetic that ultimately determines whether a business survives.
1. The Hardware Reality: Bound by Memory, Not Compute
Before discussing strategies, it is worth internalising one number. The NVIDIA A100 can perform roughly 312 TFLOPS of BF16 matrix multiplications. It can read from its HBM2e memory at roughly 2 TB/s. A 70B-parameter model in 16-bit precision weighs about 140 GB — meaning streaming all weights once takes about 70 milliseconds. Yet that same operation involves ~70 billion multiply-accumulates, which at peak throughput would take under 1 millisecond to compute.
The ratio is roughly 70:1. Your GPU can do arithmetic 70× faster than it can load the data needed for that arithmetic. For any batch size below a certain threshold, inference is memory-bandwidth bound, meaning the limiting factor is always "how fast can I get these weights into the compute units," not "how many FLOPs can I do per second." Batching is the lever that shifts you from memory-bound toward compute-bound, and nearly every inference optimization in existence is trying to move in that direction.
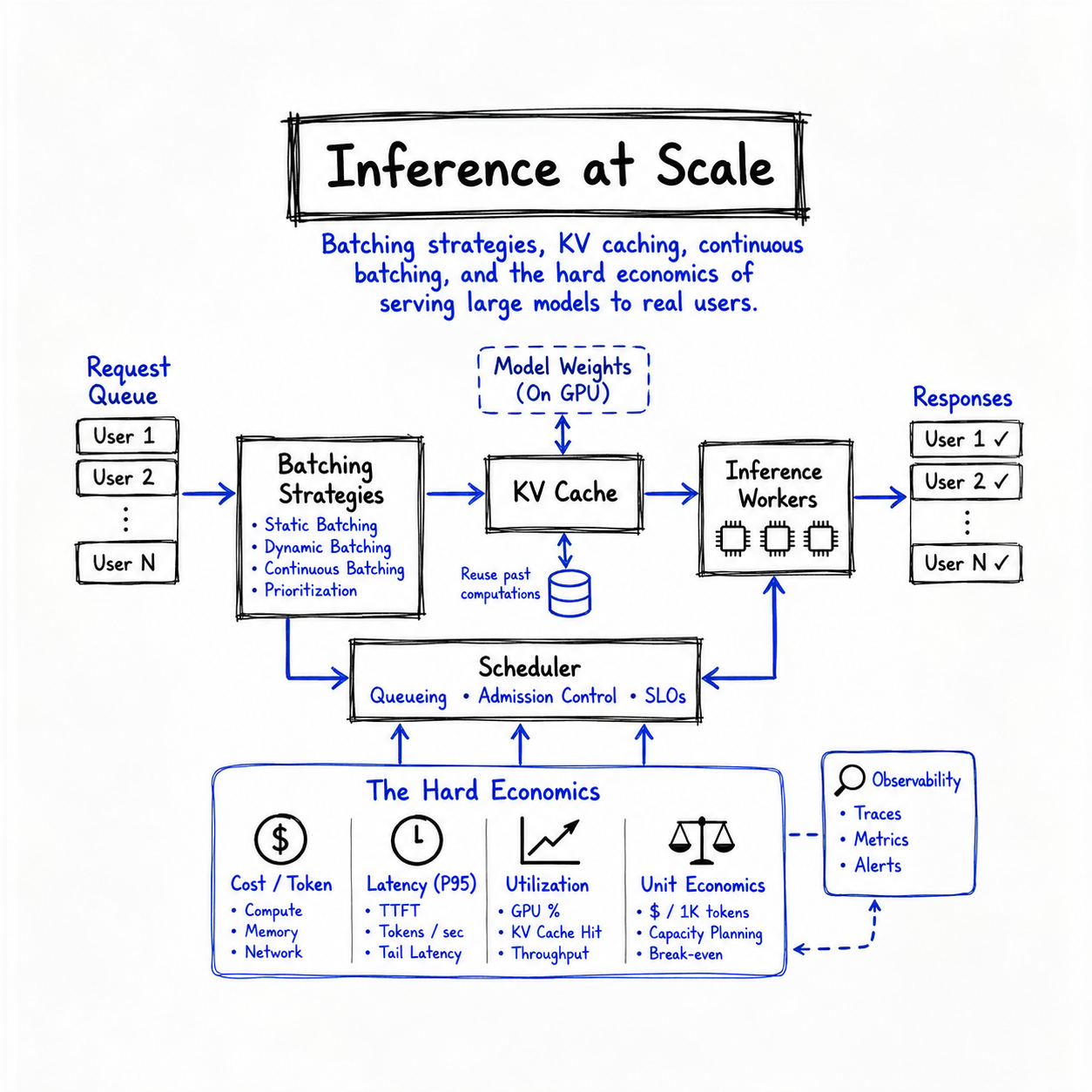
2. Static Batching: The Baseline (and Its Problem)
The most straightforward way to improve throughput is to run multiple requests through the model at the same time. This is static batching: you wait until you have N requests, pad all their sequences to the same length, and run them as a single tensor. The GPU sees a batch of shape [N, seq_len, d_model] and does arithmetic on all of it at once.
It works. But it has a brutal efficiency problem rooted in the nature of language generation. Requests arrive at different times and finish at different lengths. If you receive five requests simultaneously and three of them ask for a one-sentence answer while two ask for a five-paragraph essay, everyone has to wait for the two long requests. The three short requests finish and sit idle, occupying GPU memory and blocking the batch from accepting new work.
This padding waste compounds with sequence length variance, which in real deployments is enormous. A code generation request might produce 2,000 tokens; a classification request might produce 3. Batching them together means the short request occupies a batch slot for 99.85% of the batch's lifetime while doing no useful work.
3. KV Caching: The Memory-Compute Tradeoff at the Heart of Everything
Before we can understand continuous batching, we need to understand what makes memory the binding constraint in inference: the KV cache. In a transformer, every attention layer computes queries, keys, and values for every token in the context. During autoregressive generation, the context grows by one token per step — but the keys and values for all previous tokens don't change. Computing them again every step would be catastrophically wasteful.
The solution is to cache the key and value tensors for every token, every layer, as they're generated. On each new step, you only compute the new token's query, retrieve cached keys and values for all prior tokens, and compute attention. This is the KV cache, and it is the single largest consumer of GPU memory during inference — often dwarfing the model weights themselves for long-context requests.
This is not a minor detail. KV cache memory pressure is the primary limiter on batch size for long-context requests, and batch size is the primary lever for GPU utilization. The entire field of inference optimization is, in a large part, a battle against KV cache memory growth.
Prefix caching (prompt caching)
A powerful optimization falls out of the KV cache structure: if multiple requests share a common prefix — the same system prompt, the same few-shot examples, the same long document being queried repeatedly — the key-value tensors for that prefix only need to be computed once. Subsequent requests that start with the same prefix can reuse the cached KV tensors directly, turning what would have been a full prefill pass into a cheap lookup.
This is called prefix caching or prompt caching, and it is now a standard feature in production inference systems. When an assistant always injects a 2,000-token system prompt, prefix caching eliminates the recomputation cost for that prefix on every request. At scale, this can halve prefill latency and meaningfully reduce compute costs for prompt-heavy workloads.
4. Continuous Batching: The Scheduling Revolution
The insight that broke static batching's efficiency ceiling is deceptively simple: instead of waiting for an entire batch to finish before accepting new requests, you insert new requests into the batch the moment a slot opens up. This is continuous batching (also called dynamic batching or iteration-level scheduling), and it transformed production inference economics.
In a standard transformer forward pass, each request in the batch contributes independently to the batch dimension. There is nothing fundamentally requiring all requests to have entered and exited together. The scheduler can, at every single decoding step, inspect which sequences just finished, evict them, and fill those slots with new requests that have been waiting. The new request starts its prefill phase immediately, interleaved with the ongoing decode phases of the other sequences.
The GPU utilization improvement is dramatic. In static batching, GPU slots sit idle for the tail of every long request. In continuous batching, every idle slot is filled within one decode step. Real-world throughput improvements of 5–23× over static batching have been reported by vLLM, TGI, and other systems — with the largest gains on workloads with high variance in output length.
5. PagedAttention: Virtual Memory for the KV Cache
Continuous batching raised a new problem. The KV cache for a request grows as decoding proceeds, but the system cannot know in advance how large it will grow. Naive systems reserve a maximum-length KV buffer upfront for every request — meaning a request that generates only 50 tokens still holds memory for 4,096. This internal fragmentation (wasted reserved memory) and external fragmentation (gaps between deallocated buffers) meant GPU memory utilization remained poor even with continuous batching.
PagedAttention, introduced by the vLLM paper (Kwon et al., 2023), solved this by applying virtual memory principles to the KV cache. Instead of allocating a contiguous chunk per request, it divides KV memory into fixed-size pages (blocks of, say, 16 tokens). Each request's KV cache is stored in a set of non-contiguous pages, tracked by a block table — exactly like how an OS manages virtual memory. Pages are allocated on-demand as the sequence grows and freed immediately when the request finishes. Memory is never pre-reserved, and fragmentation is bounded by block size.
PagedAttention reduced KV cache memory waste from around 60–80% in naive systems to under 4% in benchmarks, enabling much larger effective batch sizes on the same hardware. It also enables a powerful side-effect: KV blocks for a shared prompt prefix can be literally shared between requests, giving physical memory-level prefix caching without duplication.
6. Chunked Prefill: Balancing Latency and Throughput
There is a tension at the heart of continuous batching that took the field time to appreciate. Prefilling a new request — computing KV states for its prompt — is compute-intensive and can block the decode steps of existing requests for a noticeable pause. If a new request arrives with a 10,000-token system prompt, its prefill might take 200–400ms, during which all other requests in the batch must wait before their next decode step. This causes latency spikes for ongoing conversations.
Chunked prefill addresses this by breaking a new request's prefill into smaller chunks that are interleaved with decode iterations. Instead of doing the entire prefill in one blocking pass, you process, say, 512 tokens of prefill per iteration, interspersed with regular decode steps. This smooths latency at a small throughput cost and prevents any single request's long prompt from holding up the rest of the batch.
7. The Economics: Cost Per Token at Scale
All of these techniques exist to serve one goal: reduce cost per generated token while keeping latency within acceptable bounds. Let's put some numbers to it.
An 8× A100 80GB node costs approximately $12–20/hour on major clouds. At 100% utilization running a 70B model in BF16 across all 8 GPUs, with continuous batching and PagedAttention, a well-tuned system can sustain roughly 2,000–4,000 output tokens per second. At $16/hour that is:
The utilization trap
The economic reality is that the serving cost is dominated by idle time, not active compute. A GPU serving LLM inference that is idle 80% of the time (because demand is low) costs just as much as one at 100% utilization. This is why deployment decisions — whether to run a single large model on dedicated hardware versus a shared multi-tenant cluster, whether to use spot instances, whether to implement request queuing — have as large an impact on effective economics as any algorithmic optimization.
The key metric operators track is MFU: Model FLOP Utilization — the ratio of observed FLOPS to theoretical peak. For well-optimized serving, MFU of 40–55% is considered good. Anything below 20% suggests systemic inefficiency — too small a batch, too much idle time, or architectural choices that prevent batching.
8. Quantization: Trading Bits for Bandwidth
No discussion of inference economics is complete without quantization, which directly attacks the memory-bandwidth bottleneck. If weights are 16-bit floats, streaming them takes X bytes. If they are 8-bit integers, it takes X/2 bytes — twice as fast, potentially doubling effective throughput at the same batch size. 4-bit quantization, now practical with schemes like GPTQ and AWQ, reduces weight loading to a quarter of baseline.
The accuracy cost of modern quantization is modest for most tasks. INT8 weight quantization is essentially lossless. 4-bit (W4A16 — 4-bit weights, 16-bit activations) loses a small but measurable amount of quality on complex reasoning benchmarks, but the throughput and cost gains can be substantial. A 70B model in 4-bit fits on a single 8× A100 node with room for large batch sizes; the same model in BF16 spans the full node just for weights.
| Precision | 70B model size | Bandwidth (A100) | Quality impact | Practical use |
|---|---|---|---|---|
| BF16 (baseline) | ~140 GB | 1× (baseline) | None | Research, fine-tuning |
| INT8 (W8A8) | ~70 GB | ~1.8× | Minimal | Production standard |
| W4A16 (GPTQ/AWQ) | ~35 GB | ~2.5× | Small on most tasks | High-throughput serving |
| W4A8 (mixed) | ~35 GB | ~3× | Noticeable on hard tasks | Cost-optimized deployments |
Putting It Together
Production LLM serving is a systems engineering problem as much as an ML problem. The techniques described here — continuous batching, KV caching, PagedAttention, prefix caching, chunked prefill, quantization — are not independent features you toggle on. They interact in deep ways. PagedAttention enables the memory management that makes continuous batching work at scale. Prefix caching is only possible because the KV cache has block-level granularity. Chunked prefill only matters because continuous batching created the latency tension in the first place.
What unifies them is the same insight repeated at every level: LLM inference is bottlenecked by memory bandwidth, and every optimization is about either reducing the amount of memory traffic or making that traffic more efficiently utilized. Batching amortises weight loading across more tokens. KV caching eliminates redundant recomputation. PagedAttention reduces waste in the cache itself. Quantization makes each byte of bandwidth do more work.
The infrastructure layer — vLLM, TGI, TensorRT-LLM, SGLang — packages these ideas into systems that operators can actually run. Understanding the principles beneath them is what lets you reason about where performance bottlenecks come from, when to expect diminishing returns, and what the cost-quality tradeoffs look like as you scale from a prototype to a service that millions of people depend on.