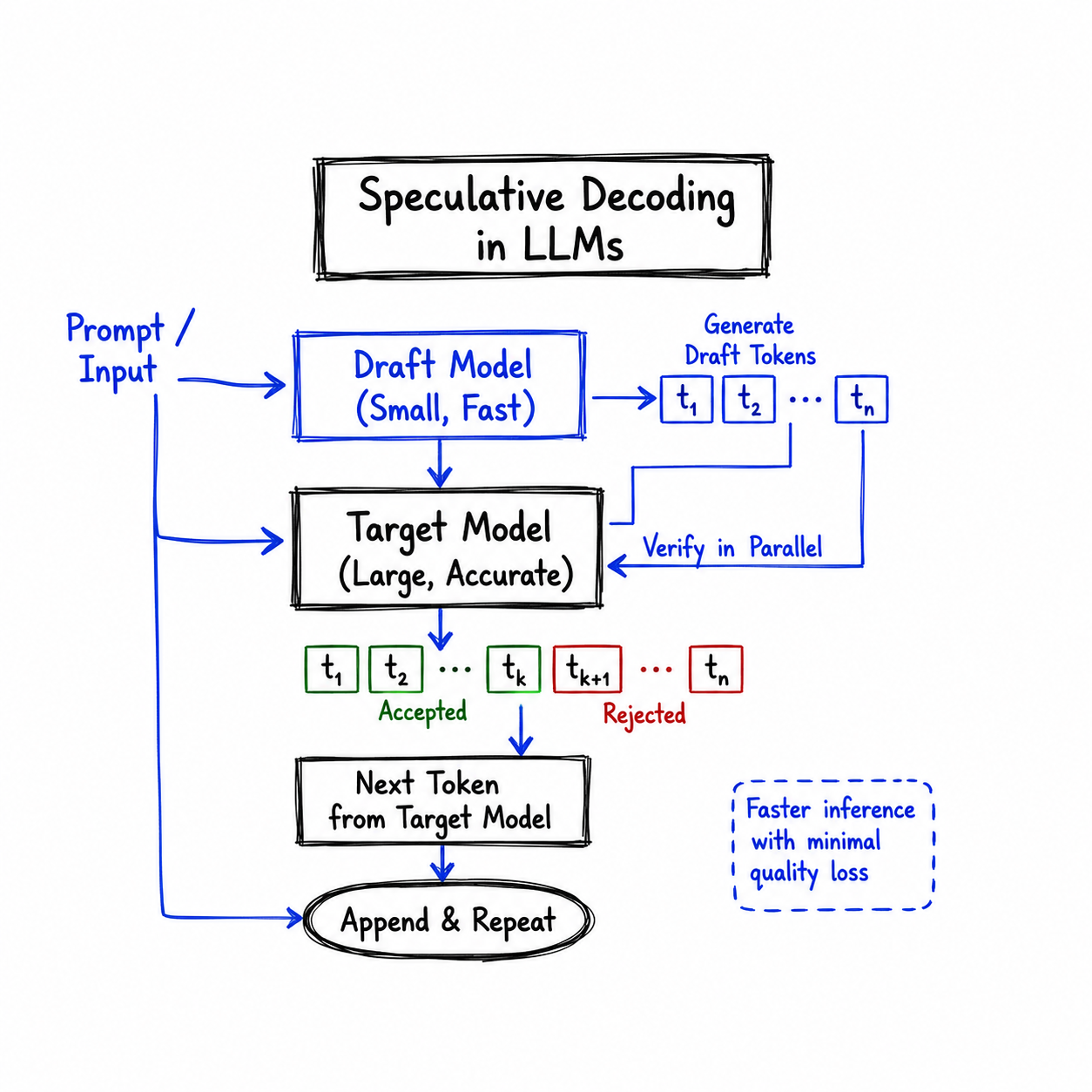
Language models generate text one token at a time. That sequential constraint is not an accident, it exists because each token depends on all the ones before it. But it comes with a serious cost! you cannot parallelise across the sequence. Every forward pass through a 70b-parameter model produces exactly one token, and you pay the full compute cost each time. Speculative decoding is a technique that breaks this bottleneck without compromising output quality. The core idea is elegant, use a small fast model to guess several tokens ahead, then verify those guesses in a single batched pass through the large model. When the guesses are right, and they often are you get multiple tokens for the price of one verification step. The result is identical output to standard autoregressive decoding, just faster. Not an approximation. Not a trade-off. A genuine free lunch, at least when the stars align.
1. The Bottleneck: Why Decoding Is Slow
To understand why speculative decoding works, you first need to understand what makes inference slow in the first place. Modern LLM inference is memory-bandwidth bound, not compute bound. This is a subtle but important distinction. A GPU has far more raw floating-point throughput than it can use when running a single forward pass, most of the silicon sits idle, waiting for weights to be loaded from HBM memory. The bottleneck is not the arithmetic; it is the time it takes to stream 70 billion parameters from memory into the compute units. This means that whether you run the model on a batch of 1 token or a batch of 8 tokens, the memory-loading cost is roughly the same. You are paying for the weight reads either way. Batching across the sequence dimension is essentially free, up to a point. Speculative decoding exploits exactly this asymmetry.
Key insightRunning the large model on a batch of 8 candidate tokens costs about the same wall-clock time as running it on 1. If you can generate those 8 candidates cheaply, you have effectively multiplied throughput by up to 8×.
2. The Mechanism: Draft, Then Verify
Speculative decoding introduces two models:
The draft model (also called the proposer or small model) is fast and cheap, typically 7 to 100× smaller than the target. It autoregressively generates a short sequence of K candidate tokens called a draft.
The target model (the large model you actually care about) then receives the entire draft sequence at once and scores every position in a single forward pass. It produces a probability distribution for each position. The algorithm then decides, token by token, whether to accept or reject each draft token, and the decision is made in a statistically rigorous way that guarantees the final output distribution exactly matches what the target would have produced on its own.
The interactive demo below animates a full cycle:
A few things are worth noting about what just happened. The draft model generated four tokens greedily in sequence, each one conditioned on the previous. The target model then scored all four in one shot. Tokens that matched the target's distribution were accepted; the first mismatch was rejected and replaced with a token sampled from the target's corrected distribution. Crucially, one "bonus" token is always produced: after the last accepted draft token, the target model has already computed a distribution for the next position, so it samples one additional token for free.
3. The Acceptance Criterion: Staying Lossless
The magic, and the subtlety, of speculative decoding is in the acceptance rule. A naive approach would just accept a draft token if it looks plausible. But that would silently change the output distribution, which is unacceptable for production systems.
The correct algorithm uses a rejection sampling scheme introduced by Leviathan et al. (2023). Let q(x) be the draft model's probability for token x, and p(x) be the target model's probability. The acceptance rule is:
This is a form of rejection sampling. When the target model agrees with the draft, or is even more confident, the token is accepted with probability 1. When the target is less confident than the draft, the token is accepted with probability p/q < 1, and rejections steer the output back toward the target's distribution. The key theorem is that the marginal distribution of the output sequence is identical to the target model's distribution, regardless of how good or bad the draft is.
Lossless guarantee: Speculative decoding produces exactly the same distribution as standard autoregressive decoding from the target model. It is not an approximation. The draft model only affects speed, never quality.
4. The Speedup: When Does It Actually Help?
The expected speedup depends on a single key quantity: the acceptance rate α, the average fraction of draft tokens accepted per cycle. If you generate K draft tokens and the acceptance rate is α, the expected number of tokens produced per cycle is:
The speedup is bounded by the draft overhead and the target model's batch tolerance. In practice, empirical speedups range from 2× to 3.5× on typical text generation tasks with well-matched draft models.
The acceptance rate is the fulcrum. It is high when the draft model is closely aligned with the target, same vocabulary, similar training data, ideally distilled from the target itself. It degrades on tasks the draft model handles poorly relative to the target: complex reasoning, rare languages, highly structured formats. In those regimes speculative decoding may offer little benefit, and the draft overhead can even hurt throughput.
5. The Verification Pass: A Diagram
Below is an annotated diagram of what happens inside a single speculative decoding cycle, draft generation on the left, verification and acceptance on the right.
6. Practical Considerations
When speculative decoding helps most
The technique shines on tasks where the next token is predictable: fluent prose continuation, code completion within a known style, translation of common phrases, and factual retrieval over familiar domains. Acceptance rates of 75–90% are common in these settings.
When it helps least
Speculative decoding degrades toward no benefit, and can even introduce overhead, when the draft model is poorly aligned with the target's distribution. Tasks that push the target model beyond the draft's competence fall into this category: highly technical reasoning chains, low-resource languages, and adversarial or out-of-distribution inputs. In the worst case, nearly every draft token is rejected, and you are paying the draft overhead for nothing.
KV cache management
When draft tokens are rejected mid-sequence, the key-value cache for those positions must be discarded. Modern implementations manage this efficiently by keeping the KV cache only for accepted tokens and appending after each verified cycle. The memory overhead is modest: the draft model maintains its own KV cache, which is proportionally smaller due to the smaller model size.
Putting It Together
Speculative decoding is one of the cleaner ideas in modern inference engineering. It works because LLM inference is memory-bound, not compute-bound, which means batching tokens together in a single target forward pass is nearly free. The draft model provides those tokens cheaply. The rejection sampling acceptance criterion guarantees losslessness. And the practical speedups of 2–3× make it compelling enough that most serious inference stacks, vLLM, TGI, TensorRT-LLM, ship some form of it as a default option.
The deeper lesson is about the relationship between correctness and efficiency in probabilistic systems. The acceptance criterion is not a hack, it is a theorem. You can speculate aggressively, reject freely, and still guarantee that your output is indistinguishable from a model that never speculated at all. Efficiency and faithfulness do not have to trade off. Sometimes, with the right algorithm, you can have both.